Hdaoop YARN安装
安装Hadoop,解压Hadoop安装包,在/opt/bpasoftware进行解压
tar -zxvf hadoop-2.6.0.tar.gz
安装包路径如有更换,下面相关配置也需要替换修改
修改环境变量,在/etc/profile文件结尾添加下列内容:
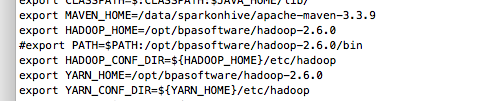
export HADOOP_HOME=/opt/bpasoftware/hadoop-2.6.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_HOME=/opt/bpasoftware/hadoop-2.6.0
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
使环境变量生效
source /etc/profile #生效环境变量
注:有时候修改了/etc/profile文件,执行命令source之后还是不能达到正常的效果,则需要重启机器,看问题是否能解决。
配置 Hadoop(需要配置以下7个文件)
- hadoop-env.sh
- yarn-env.sh
- slaves
- core-site.xml
- hdfs-site.xml
- maprd-site.xml
- yarn-site.xml
进入Hadoop配置目录
cd /opt/bpasoftware/hadoop-2.6.0/etc/hadoop
- 在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
在yarn-env.sh中配置JAVA_HOME
# some Java parameters export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77在slaves中配置slave节点的ip或者host
bpa2 bpa3 (同hosts一致)修改core-site.xml配置文件
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/bpasoftware/hadoop-2.6.0/etc/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://bpa1:9000</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration>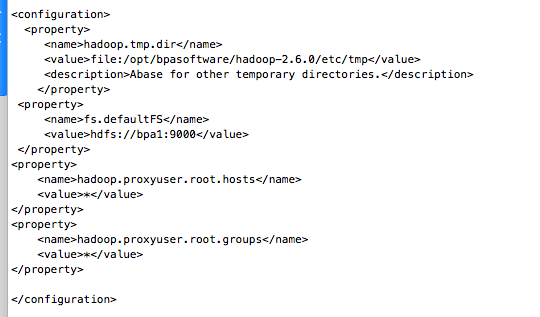
修改hdfs-site.xml配置文件
注:dfs.replication的值集群个数,此处值为3
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/bpasoftware/hadoop-2.6.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/bpasoftware/hadoop-2.6.0/tmp/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>bpa1:9001</value> </property> </configuration>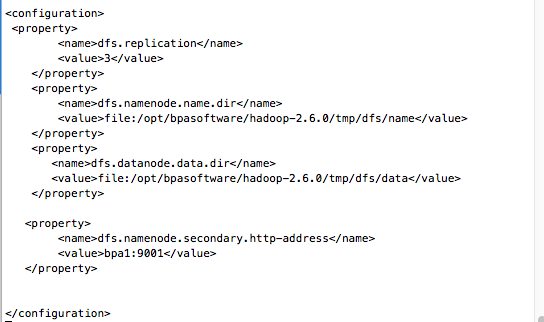
修改mapred-site.xml配置文件
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
修改yarn-site.xml配置文件
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>bpa1:8032</value> </property> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>bpa1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>bpa1:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>bpa1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>bpa1:8088</value> </property> <!-- 开启日志聚合 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name> <value>98.5</value> </property> <!-- 日志聚合HDFS目录 --> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/opt/bpasoftware/hadoop-2.6.0/yarn-logs</value> </property> <!-- 日志保存时间3days,单位秒 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>25920000</value> </property> <property> <name>yarn.log.server.url</name> <value>http://bpa1:19888/jobhistory/logs</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>将配置好的hadoop-2.6.0文件夹分发给所有slaves节点
scp -r /opt/bpasoftware/hadoop-2.6.0 用户名@主机: /opt/bpasoftware
启动 Hadoop,在 master节点上执行以下操作,就可以启动 Hadoop
cd /opt/bpasoftware/hadoop-2.6.0 #进入hadoop目录
bin/hadoop namenode -format #格式化namenode
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh #启动yarn
验证 Hadoop 是否安装成功
可以通过jps命令查看各个节点启动的进程是否正常
在 master 上应该有以下几个进程:

在每个slave上应该有以下几个进程:

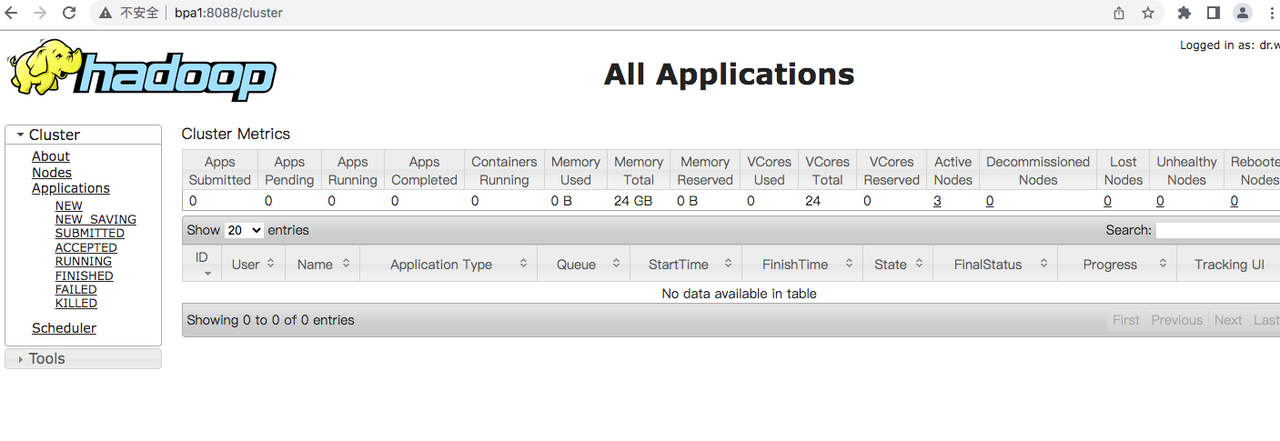
在浏览器中输入 http://bpa1:8088 ,可以看到 Hadoop 的管理界面

Seven

010-62962343-690

liujx@actionsoft.com.cn
感谢您对该文档的关注!如果您对当前页面内容有疑问或好的建议,请与我联系。如果您需要解答相关技术问题请登录AWS客户成功社区