Spark安装
安装Spark,解压Spark安装包,在/opt/bpasoftware进行解压
tar -zxvf spark-2.0.2-bin-hadoop2.6.tgz
配置 Spark
cd /opt/bpasoftware/spark-2.0.2-bin-hadoop2.6/conf #进入Spark配置目录
cp ./spark-env.sh.template spark-env.sh #从配置模板复制
打开spark-env.sh配置文件vim spark-env.sh,在文件结尾添加下列内容:
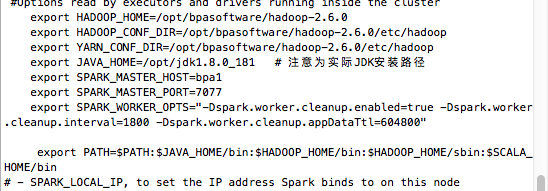
export HADOOP_HOME=/opt/bpasoftware/hadoop-2.6.0 #实际hadoop安装路径
export HADOOP_CONF_DIR=/opt/bpasoftware/hadoop-2.6.0/etc/hadoop
export YARN_CONF_DIR=/opt/bpasoftware/hadoop-2.6.0/etc/hadoop
export JAVA_HOME=/opt/jdk1.8.0_181 #注意为实际JDK安装路径
export SPARK_MASTER_HOST=bpa1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval=1800 -Dspark.worker.cleanup.appDataTtl=604800"
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
打开slaves文件,
vim slaves
在slaves文件中填上slave主机名
bpa2
bpa3
将配置好的spark-2.0.2-bin-hadoop2.6文件夹分发给所有slaves节点
scp -r /opt/bpasoftware/spark-2.0.2-bin-hadoop2.6 用户名@主机:/opt/bpasoftware
启动Spark
sbin/start-all.sh
验证 Spark 是否安装成功
可以通过jps命令查看各个节点启动的进程是否正常
主节点上启动了Master进程:

在 slave 上启动了Worker进程:

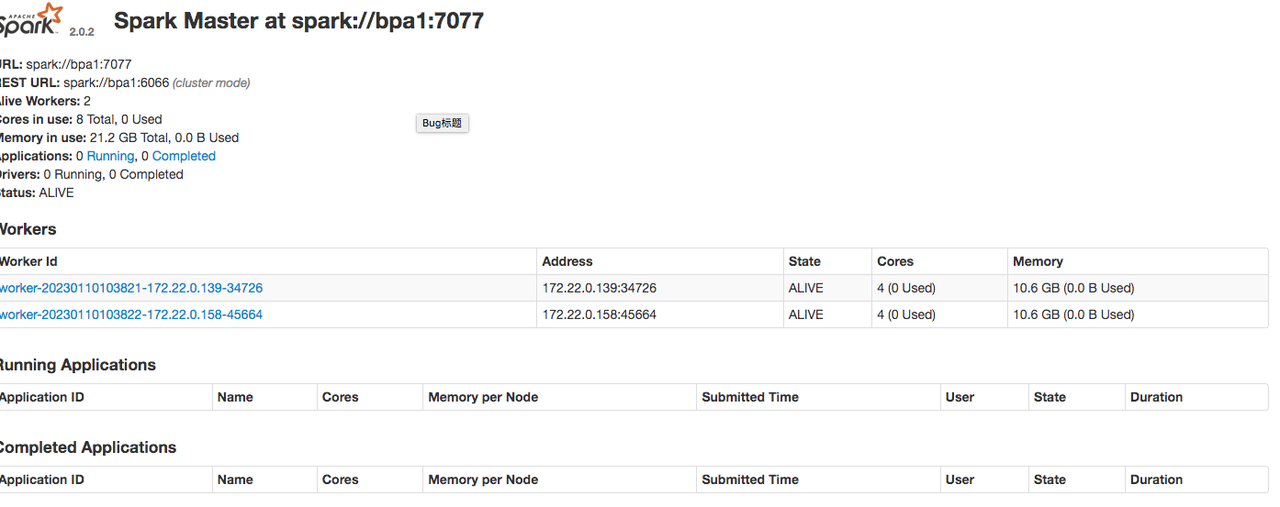
进入Spark的Web管理页面:http://bpa1:8080

Seven

010-62962343-690

liujx@actionsoft.com.cn
感谢您对该文档的关注!如果您对当前页面内容有疑问或好的建议,请与我联系。如果您需要解答相关技术问题请登录AWS客户成功社区