算法包部署
spark-analysis-server 是一个高性能的算法服务模块。为确保其在 Spark 及相关生态系统中的稳定性和兼容性,您需要遵循特定的部署与配置步骤。
请注意,如果您接收到的模块命名为
spark-bpa或spark-pmi,它们在功能上与spark-analysis-server是等同的。您可以选择重新命名此模块为spark-analysis-server或在解压后进行更名,然后按照相关指导进行部署。1. 解压算法包
首先,我们要解压缩算法包 spark-analysis-server.tar.gz。
tar -zxvf spark-analysis-server.tar.gz
若执行上述命令出现以下错误:
[root@localhost opt]# tar -zxvf spark-analysis-server.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
则尝试执行以下命令:
tar -xvf spark-analysis-server.tar.gz
2. MySQL数据库配置
确保 MySQL 服务已经安装并正在运行。
登录MySQL
cd /usr/local/mysql/bin/
mysql -u 用户名 -p密码
新建 hahivetest 数据库(算法包配置中用到)
注意:若在上述Hive安装配置的启动 Hive步骤中已经在MySQL中创建了该数据库,则该步骤跳过。
mysql> create database hahivetest; mysql> quit;
3. 算法包配置
进入 local_db_info.properties 文件进行编辑:
vim local_db_info.properties
3.1 配置 MySQL 连接信息
确保正确配置了 MySQL 数据库的连接信息:
spring.datasource.url=jdbc:mysql://172.22.0.173:3306/hahivetest?characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.datasource.username=root
spring.datasource.password=mysqlPassword
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
上述信息中的url中的IP信息、username、password替换成真实MySQL连接信息
3.2 配置Hive连接地址
spring.datasource.hive.url=jdbc:hive2://172.22.0.173:10000/default?allowMultiQueries=true
spring.datasource.hive.username=
spring.datasource.hive.password=
spring.datasource.hive.driver-class-name=org.apache.hive.jdbc.HiveDriver
上述信息中的url中的IP信息替换成Hive安装的服务器IP地址,username、password不用调整
3.3 配置 Spark Master 地址
确保 Spark master 地址是正确的:
spark.master=spark://172.22.0.173:7077
3.4 配置 HDFS 地址
配置 HDFS 存储地址:
hdfs.address=hdfs://172.22.0.173:9000/tmp/
3.5 配置 ASLP 地址
若使用BPA进行流程绩效分析,则配置以下内容:
aws.bpa.aslp=http://172.16.0.104:8088/portal/r/jd?cmd=API_CALL_ASLP&sourceAppId=com.actionsoft.apps.coe.bpa.advanced&aslp=aslp://com.actionsoft.apps.coe.bpa.advanced/sparkServerResponse&authentication=spark
若使用PMI进行流程挖掘洞察,则配置以下内容:
aws.pmi.aslp=http://172.16.0.104:8088/portal/r/jd?cmd=API_CALL_ASLP&sourceAppId=com.actionsoft.apps.coe.pmi&aslp=aslp://com.actionsoft.apps.coe.pmi/sparkServerResponse&authentication=pmi
提示: 上述配置信息需要根据实际环境进行修改,
http://172.16.0.104:8088/portal/r指BPM平台的部署地址。3.6 配置ck.properties
url=jdbc:clickhouse://172.22.0.139:8123/default (clickhouse url) driver=ru.yandex.clickhouse.ClickHouseDriver (clickhouse driver) user=default (clickhouse username) password=123456 (clickhouse password) spring.datasource.click.initialSize=20 spring.datasource.click.maxActive=100 spring.datasource.click.minIdle=10 spring.datasource.click.maxWait=6000
解释:
这些配置为应用程序指定了连接ClickHouse数据库的详细信息:
url: 定义了ClickHouse数据库的JDBC连接URL。指定的是位于172.22.0.139的ClickHouse实例,端口为8123,使用的是default数据库,根据你的 ClickHouse 服务进行修改。driver: 指定了用于连接ClickHouse数据库的JDBC驱动类名。user: 用于数据库连接的用户名,这里为default,根据你的 ClickHouse 服务进行修改。password: 与上述用户名对应的密码,这里为123456,根据你的 ClickHouse 服务进行修改。
以下配置是针对Spring的数据源连接池:spring.datasource.click.initialSize: 连接池启动时的初始连接数量。spring.datasource.click.maxActive: 连接池中允许的最大活动连接数量。spring.datasource.click.minIdle: 连接池中保持的最小空闲连接数量。spring.datasource.click.maxWait: 当连接池耗尽时,等待连接释放的最大时间(单位:毫秒)。
简而言之,这些配置为应用程序提供了连接ClickHouse数据库的详细信息和连接池参数。
4. 启动服务
nohup ./start.sh &
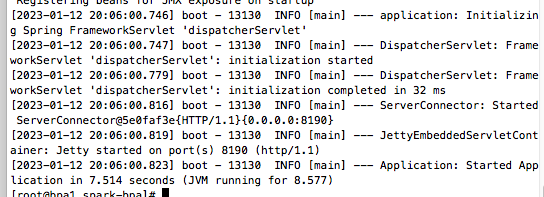
此时,你应该能看到相关日志显示服务已经成功启动.
:bulb:常见问题
Q: 我在访问HDFS时遇到了“Permission denied”错误。如何解决?
Permission denied: user=anonymous, access=WRITE, inode="/user/hive/warehouse":root:supergroup:drwxr-xr-xat
A: 这是一个HDFS权限问题。你可以通过给Hive的warehouse目录授予相应的权限来解决这个问题。请执行以下命令:
hadoop dfs -chmod -R 777 /user/hive/warehouse/
注意:该操作将给所有用户对该目录的读、写、执行权限,建议根据实际需要进行权限配置,以防不必要的风险。
Q: 我需要生成一个日期范围内的所有日期的CSV文件。应该如何操作? A: 你可以使用generate_dim_date.sh脚本并传入开始和结束日期作为参数来生成所需的CSV文件。例如,要生成从2010-01-01到2025-01-01的日期数据,执行:
generate_dim_date.sh 2010-01-01 2025-01-01
执行完成后,会在指定路径下生成名为date_dim.csv的文件。
Q: 我想将生成的日期数据导入到Hive的dim_time表中。有什么方法可以实现?
A: 你可以使用Hive的load data命令来实现。首先,确保已经在Hive中创建了dim_time这个表。然后,执行以下命令:
load data local inpath '/opt/date_dim.csv' overwrite into table dim_time;
注意:确保文件
/opt/date_dim.csv存在并且是可读的。此外,“overwrite”意味着如果表中已经有数据,它们将被新数据覆盖。如果不想覆盖,可以去掉“overwrite”关键字。
Q: 启动Spark算法服务时启动失败,nohup.out日志出现了出现了以下错误是什么原因?
Thu Aug 10 22:02:10 EDT 2023 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
[2023-08-10 22:02:11 012] [ERROR] SpringApplication.handleRunFailure(827) - Application startup failed
java.lang.IllegalStateException: Failed to execute CommandLineRunner
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:809)
A: 在Spark算法服务中local_db_info.properties的MySQL数据库连接语句增加&useSSL=false,例如
spring.datasource.url=jdbc:mysql://172.16.2.246:3306/bpa?characterEncoding=utf8&allowMultiQueries=true&useSSL=false
Q: 启动Spark算法服务时启动失败,nohup.out日志出现了出现了以下错误是什么原因?
[2023-08-14 07:12:46 469] [INFO ] Utils.parseURL(320) - Supplied authorities: 172.16.2.246:10000
[2023-08-14 07:12:46 470] [INFO ] Utils.parseURL(439) - Resolved authority: 172.16.2.246:10000
[2023-08-14 07:12:46 606] [WARN ] HiveConnection.<init>(190) - Failed to connect to 172.16.2.246:10000
[2023-08-14 07:12:46 608] [ERROR] SpringApplication.handleRunFailure(827) - Application startup failed
java.lang.IllegalStateException: Failed to execute CommandLineRunner
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:809)
at org.springframework.boot.SpringApplication.callRunners(SpringApplication.java:790)
at org.springframework.boot.SpringApplication.afterRefresh(SpringApplication.java:777)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:308)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1191)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1180)
at com.actionsoft.apps.spark.Application.main(Application.java:26)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:54)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://172.16.2.246:10000/default?allowMultiQueries=true: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:209)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at com.actionsoft.apps.spark.spark.utils.JDBCUtils.getHiveConnection(JDBCUtils.java:45)
at com.actionsoft.apps.spark.spark.utils.JDBCUtils.getConnection(JDBCUtils.java:68)
at com.actionsoft.apps.spark.spark.utils.DaoUtils.creatTable(DaoUtils.java:28)
at com.actionsoft.apps.spark.spark.utils.InitTable.run(InitTable.java:36)
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:806)
... 12 more
A:
错误的核心部分是:User: root is not allowed to impersonate anonymous,这意味着尝试使用root用户去模拟(或代表)anonymous用户,但Hadoop的安全设置不允许这样做。这通常与Hadoop的用户代理(impersonation)权限有关。
下面是一些建议的解决方案:
1. 更改用户:不使用root用户来连接Hive。通常,使用root用户进行操作不是一个好的实践,尤其是在生产环境中。
2. 更改代理设置:如果你确定需要使用root用户来代表其他用户,那么可以在Hadoop的配置文件core-site.xml中更改用户代理设置。可以设置以下属性:
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
这将允许root用户从任何主机代表任何组的用户。但请注意,这样做会增加安全风险。 3. 检查Hive配置:确保Hive的配置没有明确要求使用anonymous用户,或者确保你的应用程序或脚本没有尝试使用该用户。
4. 检查Kerberos设置(如果使用):如果你的集群启用了Kerberos认证,确保Kerberos的principals和keytabs都正确配置,并且与你尝试连接的用户匹配。
总之,这个错误是因为权限配置不允许你所尝试的操作,你需要根据实际需求和安全限制来决定最佳的解决方案。
Q: 启动Spark算法服务时启动失败,nohup.out日志出现了出现了以下错误是什么原因?
Caused by: java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=anonymous, access=WRITE, inode="/user":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:238)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:179)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6512)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6494)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6446)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:4248)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4218)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4191)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:813)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:600)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2039)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2035)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2033)
)
at org.apache.hive.jdbc.HiveStatement.waitForOperationToComplete(HiveStatement.java:349)
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:251)
at com.actionsoft.apps.spark.spark.utils.JDBCUtils.executeSQLBatch(JDBCUtils.java:80)
at com.actionsoft.apps.spark.spark.utils.DaoUtils.creatTable(DaoUtils.java:33)
at com.actionsoft.apps.spark.spark.utils.InitTable.run(InitTable.java:36)
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:806)
... 12 more
A:
此错误表示在尝试写入 Hadoop 分布式文件系统(HDFS)时遇到了权限问题。具体来说,错误发生在尝试写入 /user 目录时,由于权限被拒绝而失败。
user=anonymous: 正在尝试执行写入操作的用户是 "anonymous"。access=WRITE: 正在尝试执行的操作是写入。inode="/user":root:supergroup:drwxr-xr-x: 目标路径是/user,属主是 "root",所属组是 "supergroup",并且权限设置为drwxr-xr-x。 根据这些信息,问题似乎是 "anonymous" 用户没有写入/user目录的权限。
解决此问题的一种可能方法是更改 /user 目录的权限,以便 "anonymous" 用户(或 "anonymous" 所属的组)具有写入权限。如果 "anonymous" 用户应该有这样的权限,您可以通过运行以下 HDFS 命令来更改权限:
hadoop fs -chmod -R 777 /user
这将赋予所有用户对 /user 目录的读、写和执行权限。请注意,这是一项重大更改,可能会带来安全风险,因此在生产环境中使用之前,请确保与您的团队或组织的安全政策相一致。
如果 "anonymous" 用户不应具有对该目录的写入权限,那么您可能需要检查为什么此用户正在尝试执行此操作,并相应地更正代码或配置。可能的解决方案可能包括使用具有适当权限的不同用户执行操作,或者将数据写入用户有权访问的不同目录。


