Hdaoop安装
注意:如果安装包路径发生变化,后续相关配置也需要进行相应的修改。
集群部署
1. 解压Hadoop安装包
在/opt目录下解压Hadoop安装包:
tar -zxvf hadoop-2.6.0.tar.gz
2. 设置环境变量
在/etc/profile文件的结尾添加:
export HADOOP_HOME=/opt/hadoop-2.6.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_HOME=/opt/hadoop-2.6.0
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
然后激活环境变量:
source /etc/profile
注:若修改了
/etc/profile后,source命令无法生效,则尝试重启机器。
3. 配置Hadoop
进入Hadoop配置目录:
cd $HADOOP_HOME/etc/hadoop
3.1 在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/jdk-xxx #xxx为您的JDK版本
解释:
在hadoop-env.sh中配置JAVA_HOME为Hadoop明确指定了其运行所依赖的Java环境路径,确保集群在正确和一致的Java版本下工作。
3.2 在yarn-env.sh中配置JAVA_HOME
# some Java parameters
export JAVA_HOME=/usr/lib/jvm/jdk-xxx #xxx为您的JDK版本
解释:
在yarn-env.sh中配置JAVA_HOME为YARN明确指定了其依赖的Java运行环境,确保其在指定的Java版本下稳定运行。
3.3 配置slaves文件
在Hadoop的配置中, slaves 文件用于指定哪些节点应该运行 DataNode 和 NodeManager 进程。您应该在这里列出所有的工作节点(slave节点)。
bpa2
bpa3
注意:bpa1 是我们的主节点,如果您不打算在bpa1节点上面运行 DataNode 和 NodeManager 进程,则不需要在此文件中列出。
3.4 修改core-site.xml配置文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.6.0/etc/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bpa1:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
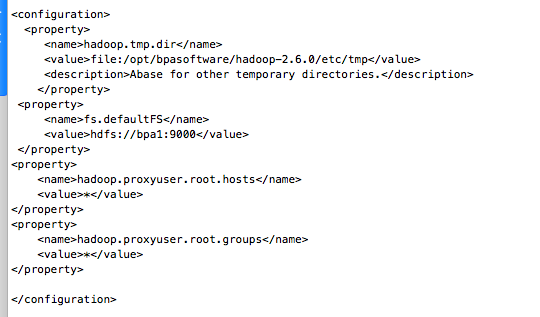
解释:
hadoop.tmp.dir定义了Hadoop的基础临时目录,存放临时数据和工作文件。fs.defaultFS指定了Hadoop文件系统(HDFS)的默认NameNode地址。hadoop.proxyuser.root.hosts配置了哪些主机可以通过代理用户root来运行Hadoop服务。hadoop.proxyuser.root.groups定义了哪些用户组可以使用代理用户root来执行Hadoop任务。
3.5 修改hdfs-site.xml配置文件
注意:dfs.replication的值应该等于集群的节点数。例如,此处为3。
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-2.6.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-2.6.0/tmp/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>bpa1:9001</value> </property> </configuration>
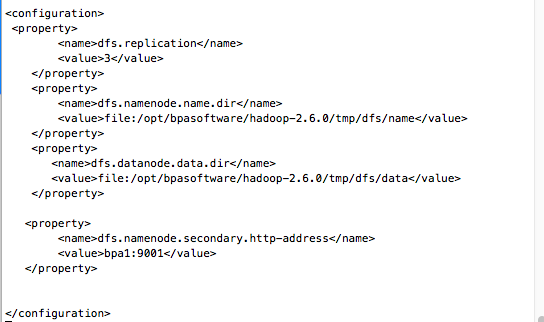
解释:
dfs.replication设置了HDFS中每个块的数量,也就是集群的节点数。dfs.namenode.name.dir定义了NameNode存储元数据的目录位置。dfs.datanode.data.dir指定了DataNode存储数据块的目录位置。dfs.namenode.secondary.http-address配置了次要NameNode的HTTP服务地址。
3.6 修改mapred-site.xml配置文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

解释:
mapreduce.framework.name 配置项指定了MapReduce作业使用yarn作为其执行框架。
3.7 修改yarn-site.xml配置文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bpa1:8032</value>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bpa1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bpa1:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bpa1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bpa1:8088</value>
</property>
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98.5</value>
</property>
<!-- 日志聚合HDFS目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/hadoop-2.6.0/yarn-logs</value>
</property>
<!-- 日志保存时间3days,单位秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>25920000</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bpa1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
解释:
yarn.nodemanager.aux-services配置了NodeManager的辅助服务,此处为MapReduce shuffle服务。yarn.nodemanager.aux-services.mapreduce.shuffle.class定义了shuffle服务的实现类。- 资源管理器(ResourceManager)的各种服务地址被指定:
3.1yarn.resourcemanager.address定义了资源管理器的通信地址。
3.2yarn.resourcemanager.scheduler.address定义了资源调度服务的地址。
3.3yarn.resourcemanager.resource-tracker.address定义了资源跟踪服务的地址。
3.4yarn.resourcemanager.admin.address定义了资源管理器的管理地址。
3.5yarn.resourcemanager.webapp.address定义了资源管理器的Web应用地址。 yarn.log-aggregation-enable开启了日志聚合功能。yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage设置了磁盘健康检查的磁盘使用率上限。yarn.nodemanager.remote-app-log-dir指定了YARN的日志聚合在HDFS中的存储位置。yarn.log-aggregation.retain-seconds定义了日志聚合的保存时长。yarn.log.server.url指定了日志服务器的URL。yarn.nodemanager.pmem-check-enabled和yarn.nodemanager.vmem-check-enabled禁用了物理和虚拟内存检查。
4. 配置分发
集群部署:将配置好的Hadoop目录分发给所有slave节点
scp -r /opt/hadoop-2.6.0 用户名@主机: /opt
5. 启动Hadoop
仅在master节点执行以下命令以启动Hadoop:
5.1 进入Hadoop目录
cd /opt/hadoop-2.6.0
5.2 首次部署时格式化 NameNode
在首次部署或需要重置HDFS时执行以下命令。请注意,这会删除所有HDFS上的数据。
bin/hadoop namenode -format
解释:
bin/hadoop namenode -format 命令用于初始化并格式化HDFS的NameNode目录结构,准备NameNode开始存储文件系统元数据。
5.3 启动 Distributed File System (DFS)
sbin/start-dfs.sh
解释:
sbin/start-dfs.sh 命令用于启动HDFS的所有守护进程,包括NameNode、SecondaryNameNode和DataNode。
5.4 启动 Yet Another Resource Negotiator (YARN)
sbin/start-yarn.sh
解释:
sbin/start-yarn.sh 命令用于启动YARN的所有守护进程,包括ResourceManager和NodeManager。
6. 验证Hadoop安装
6.1 使用jps命令检查进程:
在master节点: 执行命令后,您应该可以看到以下进程:
- NameNode
- SecondaryNameNode (或者可以看到QJM related processes, 如果您使用QJM)
- ResourceManager
如果在步骤 3.3 中,您也在 master 节点上配置了 slave 服务(如bpa1为master同时也是slave),则还应能看到:
- DataNode
- NodeManager

在每个slave节点: 执行命令后,您应该可以看到以下进程:
- DataNode
- NodeManager

6.2 通过浏览器访问Hadoop管理界面:
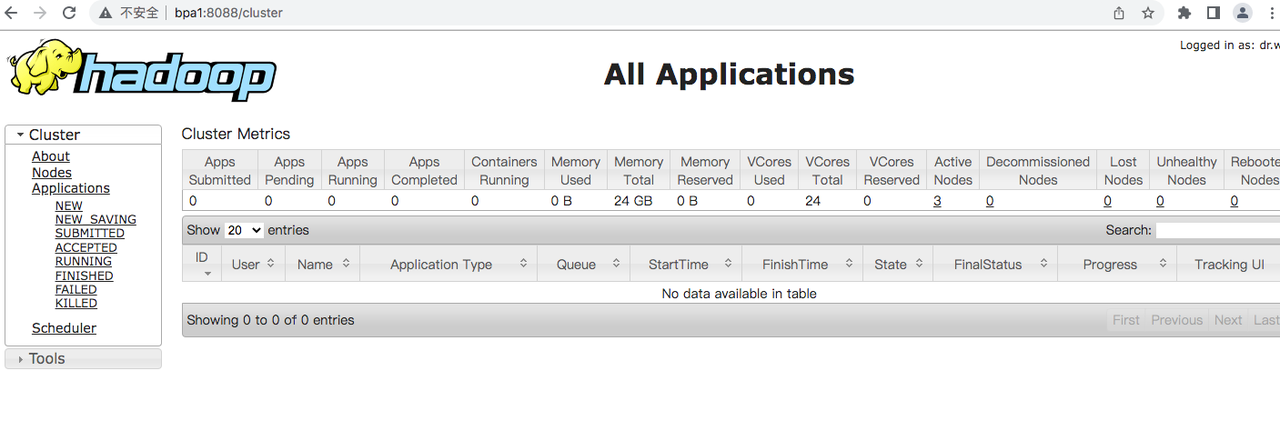
ResourceManager UI(8088端口)
- 描述: YARN的ResourceManager提供了一个Web界面,用于查看和管理集群资源以及运行的作业。
- 验证方法: 打开浏览器,访问 http://[your-namenode-ip]:8088,例如http://bpa1:8088。如果可以看到ResourceManager的主页,说明YARN正在正常运行。
 NameNode UI(50070端口)
NameNode UI(50070端口) - 描述: HDFS的NameNode同样提供了一个Web界面,允许用户查看文件系统的状态、健康状况和目录结构。
- 验证方法: 打开浏览器,访问 http://[your-namenode-ip]:50070,例如http://bpa1:50070。如果可以看到HDFS的文件系统界面,说明HDFS正在正常运行。

单机部署
注意:在伪分布模式下,Hadoop的所有组件都运行在同一台机器上。单机版是为了方便您在本地进行开发和测试,而集群版为实际生产环境准备。
1. 关闭防火墙
service iptables stop
chkconfig iptables off
或
systemctl stop firewalld
systemctl mask firewalld
若iptables未安装:
yum install -y iptables
2. 解压Hadoop安装包
在/opt目录下解压Hadoop安装包:
tar -zxvf hadoop-2.6.0.tar.gz
3. 设置环境变量
在/etc/profile文件的结尾添加:
export HADOOP_HOME=/opt/hadoop-2.6.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后激活环境变量:
source /etc/profile
注:若修改了
/etc/profile后,source命令无法生效,则尝试重启机器。
4. 配置Hadoop
进入Hadoop配置目录:
cd $HADOOP_HOME/etc/hadoop
4.1 在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/jdkxxx #xxx为您的JDK版本
4.2 在yarn-env.sh中配置JAVA_HOME
# some Java parameters
export JAVA_HOME=/usr/lib/jvm/jdkxxx #xxx为您的JDK版本
4.3 配置slaves文件
指定要运行DataNode和NodeManager进程的节点。在单机模式下,只需要列出本机。
bpa1
4.4 修改core-site.xml配置文件
<configuration>
<!-- HDFS通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bpa1:9000</value>
</property>
<!-- Hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopTmp/tmp</value>
</property>
</configuration>
解释:
fs.defaultFS: HDFS的通信地址,即NameNode的地址,伪分布模式下一般不需修改。hadoop.tmp.dir: Hadoop的临时目录。建议选择非/tmp路径。
4.5 修改hdfs-site.xml配置文件
注意: 因为是伪分布模式,只有一个节点,所以副本数设置为1。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.6 修改mapred-site.xml配置文件
提示: 默认只有mapred-site.xml.template文件,需要重命名或复制为mapred-site.xml。 ```
mapreduce.framework.name yarn
##### 4.7 修改yarn-site.xml配置文件
解释:
yarn.resourcemanager.hostname: 指定ResourceManager的运行节点,这里是本机。yarn.nodemanager.aux-services: 指定NodeManager的加载方式,这里使用MapReduce的默认混选算法。
5. 启动Hadoop
启动和管理Hadoop的步骤与集群模式相同。
6. 验证Hadoop安装
启动和管理Hadoop的步骤与集群模式相同。
:bulb:常见问题
Q: 我应该选择哪种模式进行Hadoop安装:单机模式、伪分布式模式还是完全分布式模式? A:
- 对于学习和开发,通常推荐使用单机模式或伪分布式模式。
- 对于生产环境或大数据处理,建议使用完全分布式模式。
Q: 我在启动Hadoop后,为什么看不到所有的DataNode? A:
- 检查Hadoop的日志文件,寻找任何关于DataNode的错误。
- 检查
hdfs-site.xml文件中的配置。 - 确保所有DataNode机器的防火墙没有阻止Hadoop的通信。
Q: 为什么我在启动Hadoop时收到"JAVA_HOME is not set"的错误?
A: 你需要在Hadoop环境配置文件hadoop-env.sh中设置JAVA_HOME变量。
Q: NameNode无法启动,我该怎么办? A:
- 检查Hadoop日志文件以获取详细的错误信息。
- 确保为NameNode分配了足够的内存。
- 确保HDFS目录已正确设置并具有适当的权限。
Q: 在启动Hadoop集群后,为什么我看不到JobTracker和TaskTracker? A: 从Hadoop 2.x开始,集群使用YARN进行资源管理。因此,你应该看到ResourceManager和NodeManager,而不是JobTracker和TaskTracker。
Q: 我如何解决Hadoop的端口冲突? A: 修改Hadoop配置文件中的相应端口设置。例如,在hdfs-site.xml和core-site.xml中。


