Spark安装
1. 解压Spark安装包
在 /opt 目录下解压 Spark 安装包:
tar -zxvf spark-2.3.2-bin-hadoop2.6.tgz
2. 配置 Spark
进入 Spark 的配置目录:
cd /opt/spark-2.3.2-bin-hadoop2.6/conf
从配置模板复制 spark-env.sh:
cp ./spark-env.sh.template spark-env.sh
编辑 spark-env.sh文件:
vim spark-env.sh
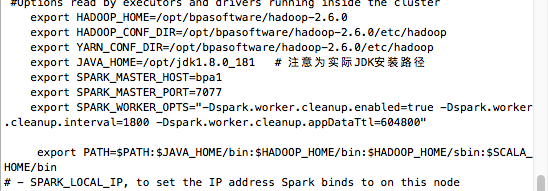
在文件结尾添加下列内容:
注意:在设置 Worker 进程的 CPU 个数和内存大小时,要注意机器的实际硬件条件。如果配置超出当前 Worker 节点的硬件条件,Worker 进程可能会启动失败。
export HADOOP_HOME=/opt/hadoop-2.6.0 #实际hadoop安装路径
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0/etc/hadoop #实际hadoop安装路径
export YARN_CONF_DIR=/opt/hadoop-2.6.0/etc/hadoop #实际hadoop安装路径
export JAVA_HOME=/usr/lib/jvm/jdkxxx #xxx为您的JDK版本
export SPARK_MASTER_HOST=bpa1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval=1800 -Dspark.worker.cleanup.appDataTtl=604800"
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
解释:
HADOOP_HOME指定了Hadoop的安装路径。HADOOP_CONF_DIR指明了Hadoop的配置文件所在目录。YARN_CONF_DIR指明了YARN的配置文件所在目录。JAVA_HOME定义了Java JDK的安装路径。SPARK_MASTER_HOST设置了Spark Master的主机名。SPARK_MASTER_PORT设置了Spark Master监听的端口号。SPARK_WORKER_OPTS设置了Spark Worker的选项,包括清理功能的开启、清理间隔和应用数据的生存时间。PATH在原有的PATH基础上追加了Java、Hadoop和Scala的命令路径。
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
3. 配置slaves文件
从配置模版复制slaves.template:
cp ./slaves.template slaves
编辑 slaves 文件:
vim slaves
在文件中填入所有应运行 DataNode 和 NodeManager 进程的主机名:
bpa1
bpa2
bpa3
注意 如果您希望 Hadoop 的主节点 (NameNode) 也扮演 DataNode 的角色,确保在
slaves文件中包含该主节点的主机名。例如,如果您的主节点主机名是bpa1,则slaves文件应该如上。 将主节点同时用作 DataNode 可以提高集群的存储和计算能力,尤其在小型或测试集群中。但请注意,在生产环境中,通常建议将 NameNode 与 DataNode 进程分开,以确保 NameNode 的稳定性和性能。
4. 分发配置文件 (仅集群部署需要)
将配置好的 spark-2.3.2-bin-hadoop2.6 文件夹分发给所有 slave 节点:
scp -r /opt/spark-2.3.2-bin-hadoop2.6 用户名@主机:/opt
5. 启动Spark
使用以下命令启动 Spark:
sbin/start-all.sh
解释:
sbin/start-all.sh 脚本用于启动Spark集群的所有组件,即同时启动Master和所有的Worker节点。
6. 验证 Spark 安装
通过 jps 命令查看各个节点上启动的进程。
主节点上应启动了 Master 进程

Slave 节点上应启动了 Worker 进程

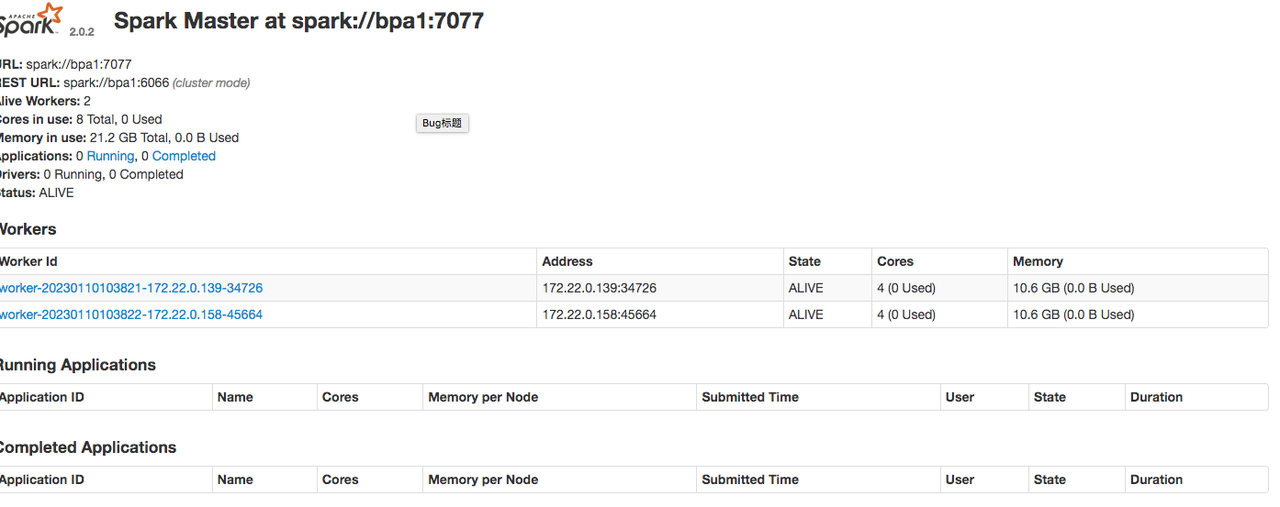
访问 Spark 的 Web 管理界面来验证安装:http://bpa1:8080
:bulb:常见问题
Q: 我已经设置了JAVA_HOME,但为什么Spark仍然报错说JAVA_HOME没有设置?
A: 确保JAVA_HOME已经在你启动Spark的同一环境中设置,并且导出到了PATH。
Q: 我如何为Spark分配更多内存?
A: 你可以使用spark.driver.memory和spark.executor.memory配置参数在spark-defaults.conf中设置。
Q: Spark的Web UI显示不了,我应该怎么办? A:
- 首先检查你的Spark集群是否正在运行。
- 确保没有防火墙或网络问题阻止你访问Web UI的端口。
Q: 当我运行Spark作业时,为什么它失败并显示“OutOfMemoryError”? A: 这可能是因为给Spark分配的内存不足。尝试增加驱动程序和执行程序的内存配置。
Q: 我如何连接Spark到我的Hadoop集群? A: 确保在安装Spark时下载了正确版本的预构建包(基于你的Hadoop版本)。然后,在Spark的配置中设置Hadoop的配置文件路径。
Q: 我可以在同一台机器上运行多个Spark版本吗? A: 是的,但是为每个版本设置一个单独的目录和环境变量。
Q: 我在哪里可以查看Spark作业的日志?
A: 默认情况下,Spark将日志写入标准输出。你也可以在Spark的Web UI中查看日志,或查找Spark应用程序的日志文件,通常位于$SPARK_HOME/logs。


